Except web 2.0 developers, no one else in the world of SEO seems to believe that search engines can actually make sense of any type of URL structure. Web developers understand codes; they can play around with different URL structures and use a variety of URL handles to either manipulate inputs received from a user or keep URLs simple and easy-to-work with but no-so-SEO-friendly! Thus, SEO experts and web developers live in two parallel universes!
For a web developer – web page response time, minimum database access calls and crawling are important. For an SEO expert, however, higher rank on Search Engine Results Pages (SERPs) is the grand Holy Grail! Read on to know how exactly a website can have SEO-friendly structure.
1. Straightforward
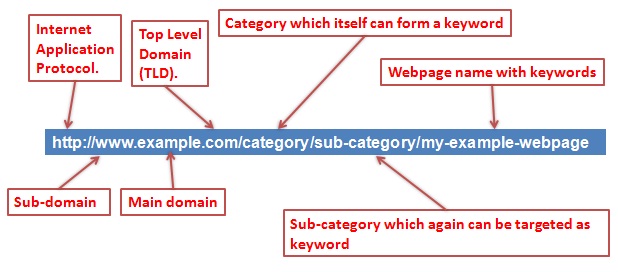
URLs on a website, at the first glance, should look really simple and indicate the content they have. Followed by the Hypertext Transfer Protocol (http://www), a URL has the domain name, sub-directory and short or long-tail name of the page, resource or file. The depth of the URL, according to the directory structure on your website, should be intuitive and strictly according to the keyword combinations you’re targeting for a specific page or complete website.
For example
yourdomainname.com/interior-design/interactive/Multitouch-tables-for-homes
is way better than
yourdomainname.com/Multitouch-tables
or
yourdomainname.com/3304/13/03/2013/multi-touch-tables
2. Avoid dynamic and relative URLs
Dynamic and relative URLs such as “www.yourdomain.com/p?903458” work well for a developer but for an SEO expert, they’re unattractive and self-damaging. While dynamic URLs have post ids, dates and other random characters in them, relative URLs have contextual characters in them. Such URLs may also have additional characters such as question marks or ampersands used to track website traffic or other parameters like user id, language etc.
Search engines love consistent URLs with ‘meaningful’ structure. These URLs are static in nature and they not only help your website to be ranked well for target keywords but also motivate users to choose your website’s listing on Search Engine Results Page over 10 others as they appear meaningful with the title. Such URLs can also be solidified easily in Google Webmaster Tools by rejecting variable URL parameters if you’ve to work with any.
3. Create an XML Sitemap
XML sitemaps are quick-guides that search engines use to index various pages on your website. These sitemaps (unlike HTML sitemaps designed for quick navigation), list various page URLs on your website. It’s a good idea to have a dynamic XML Sitemap that gets automatically updated every time a new URL is created. It helps in quick search engine indexing of newly created or updated web pages and also tells search engines which URL structure to prefer in case there are any duplicates.
4. Specify canonical URLs using a special tag
A large number of websites lose link-juice simply due to the reason that they’ve duplicate URLs and no preferred or canonical URLs are specified.
On a basic level, http://yourdomain.com/sample-url and http://yourdomain.com/sample-url/34/454 and http://yourdomain.com/p?546 might be pointing to the same page! It gets worse especially if your website is not just serving content but selling some products. In e-commerce, URLs get even more complex and there’re dozens of duplicate versions.
The outcome – search engine crawlers are confused, people are back-linking to the same page by using different URLs and you’re losing SEO benefits you could avail.
The solution to this problem is to clearly specific canonical URLs by making use of special tags. It shouldn’t, however, be used for redirects or content pagination. There’re other ways to do that.
Image Credit: Seotechn.blogspot.in